Support Vector Machine (SVM)
개념
- 분류를 위한 기준선, 즉 결정 경계선을 찾는 알고리즘이다.

- 성능을 위해 정규화 작업이 필요하다.
- 분류, 회귀에 모두 사용가능하다
용어

결정 경계(Decision Boundary)
사진상 빨간선으로, 서로다른 분륫값을 결정하는 경계이다
벡터
사진상 점들로, 데이터를 나타낸다
서포트 벡터
결정 경계선과 가장 가까운 데이터 포인트
마진
서포트 벡터와 결정 경계 사이의 거리를 말한다.
마진이 클수록 새로운 데이터에 대해 안정적으로 분류할 가능성이 높다
비용 (C)
학습 시 에러가 적은 모델보다 운영시 에러가 적은 모델이 더 좋은 모델이다

SVM은 약간의 오류를 허용하기 위해서 비용 변수를 사용한다
비용이 너무 크면 과대적합이 되어서 운영시 에러가 많은 모델이 될 수 있다
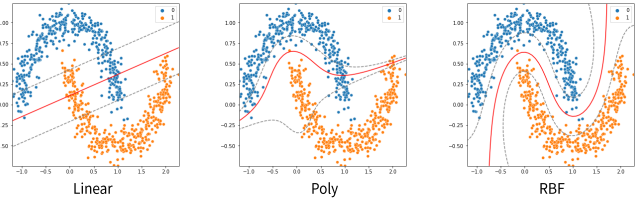
비선형 데이터셋은 Linear 말고 Poly나 RBF를 사용할수 있다
K-Fold 교차 검증(K-Fold Cross Validation)
머신러닝 모델의 성능을 보다 안정적이고 객관적으로 평가하기 위한 검증 기법입니다. 이 방법은 주어진 데이터를 여러 번 나누어 학습과 테스트를 반복함으로써, 모델이 특정 데이터셋에 과적합(Overfitting)되는 것을 방지하고, 다양한 데이터 분할에 대한 평균 성능을 측정할 수 있게 해줍니다.
K-Fold 교차 검증의 절차
- 데이터 분할
주어진 데이터셋을 K개의 서로 겹치지 않는 부분(Fold)으로 나눕니다. 각 Fold는 데이터 샘플의 비율을 동일하게 유지하도록 설정합니다. - 모델 학습 및 검증
- 각 반복(iteration)마다 K개의 Fold 중 하나를 테스트 데이터로 사용하고, 나머지 K-1개의 Fold를 학습 데이터로 사용합니다.
- 이 과정을 K번 반복하며, 매번 다른 Fold가 테스트 데이터로 사용됩니다.
- 평균 성능 계산
- 각 Fold에 대해 도출된 성능 평가 지표(예: 정확도, F1-Score 등)를 모두 합산한 후 평균값을 구합니다.
- 이 평균 성능이 최종 모델의 성능 평가 결과로 간주됩니다.
K-Fold 교차 검증의 장점
- 과적합 방지: 데이터의 특정 부분에 의존하는 모델이 만들어지는 것을 방지합니다.
- 데이터 활용 극대화: 데이터셋의 모든 샘플이 학습과 테스트에 모두 사용되므로 데이터가 적을 때 유리합니다.
- 일관된 평가: 여러 번의 검증을 통해 모델의 성능을 일관되게 평가할 수 있습니다.
K 값 선택
- K=5 또는 10: 일반적으로 5-Fold나 10-Fold가 많이 사용됩니다.
- K가 너무 크면: 학습 시간 증가.
- K가 너무 작으면: 테스트 데이터 비율이 적어 평가의 변동성이 커질 수 있습니다.
예시
만약 데이터셋을 5-Fold로 나눈다면:
- 첫 번째 반복: 1번째 Fold → 테스트, 2~5번째 Fold → 학습
- 두 번째 반복: 2번째 Fold → 테스트, 나머지 Fold → 학습
- 이런 식으로 5번 반복하여 성능 평가 후, 최종 성능을 평균내어 도출합니다.
어려운 머신러닝 알고리즘 개념.....