데이터 분석을하기 위해서 전처리 과정이 꼭 필요하다.
전처리 과정중 꼭 알아야하는 데이터프레임 변경하는법을 알아보자..
~목차~
열 이름 변경
열 추가
열 삭제
범주값 변경
범주값 만들기
결측치 찾기
결측치 제거
결측치 채우기
가변수(Dummy Variable) 만들기
1. 열 이름 변경
일부만 선택해서 변경하는 방법과 한번에 모두 바꾸는 방법이 있다.
(1) 선택해서 변경하기 - rename() 사용하기
tip.rename(columns={'바꾸고싶은 열 이름' : '바꿀 열 이름',
'바꾸고싶은 열 이름2' : '바꿀 열 이름'}, inplace = True)이런식으로 사용한다. inplace를 True로 해야 반영된다.
(2) 한번에 모두 바꾸고 싶을때
tip.columns = ['바꾸고 싶은 열 이름 1', '바꾸고 싶은 열 이름 2', '바꾸고 싶은 열 이름 3']
이렇게 나열해서 변경하면 된다. 그대로 두고싶은게 있다면 그대로 적으면 된다.
1. 열 추가
# final_amt 열 추가: final_amt = total_bill + tip
tip['final_amt'] = tip['total_bill'] + tip['tip']그냥 이렇게 추가하면 된다.
이렇게 추가하면 맨 끝에 추가된다.
# tip 열 앞에 div_tb 열 추가: div_tb = total_bill / size
tip.insert(1,'div_tb', tip['total_bill'] / tip['size'])원하는 자리에 추가하고 싶다면 insert를 사용할 수 있다.
3. 열 삭제 --> 조심히 삭제해야함!!
열 한개만 삭제하는 방법이 있고, 여러개를 한번에 삭제하는 방법이 있다.
# 열 하나 삭제: final_amt
drop_cols = ['final_amt']
tip.drop(drop_cols, axis=1, inplace=True)
#tip.drop(columns = drop_cols, inplace=True) 라고 써도 됨.
이건 열을 한개만 삭제하는 방법이다.
drop() 메소드를 사용하는 방법이고, axis = 0 이면 행 삭제를 의미하고, 0이 기본값이다. 열 삭제는 1로 해야한다.
# 열 두 개 삭제: div_tb, day
drop_cols = ['div_tb','day']
tip.drop(columns = drop_cols, inplace=True)
여러열을 삭제하고 싶으면 리스트 형태로 전달해서 삭제하면 된다.
4. 범주값 변경
머신러닝을 학습시킬때, male, female 값을 0 과 1로 바꾸면 분석과 학습에 유용하다
# Male -> 1, Female -> 0
tip['sex'] = tip['sex'].map({'Male' : 1, 'Female' : 0})이렇게 map() 메소드를 이용할 수 있다. 위의 코드는 tip 데이터프레임의 sex열에서 Male 을 1로, Female을 0 으로 바꾸는 코드이다.
map()으로 범주값을 변경하면, 매핑되지 못한 값은 null값(NaN)이 된다. 위의 코드로 예를 들자면, sex열에서 Male도 Female 도 아닌 Man 이 있다면, 그 값은 null값이 된다.
# 1 --> Male, 0 --> Female
tip['sex'] = tip['sex'].replace({1:'Male', 0:'Female'})
두번째 방법으로는 replace가 있다. 이 코드는 1을 Male로, 0을 Female로 바꾸는 코드다.
이 방법은 매핑되지 못하면 그냥 그대로 남는다. (1과 0이 아닌 2 가 있으면 그대로 2로 남는다.)
5. 범주값 만들기
- 연속값을 구간을 나누어 범주값으로 표현하는 과정을 이산화(Discretization) 라고 합니다.
- cut(), qcut() 함수를 사용하여 쉽게 이산화 과정을 수행할 수 있습니다.
- 연속값을 이산화 함으로써 더 심도있는 데이터 분석이 가능해집니다.
- 예를 들어 점수를 일정 구간으로 구분하면 점수 구간별 분석이 가능해집니다.
- 또한 데이터가 단순해져 머신러닝 학습 과정과, 모델 성능이 향상될 수 있습니다.
- 사용 방법이 다소 어렵지만 알아두면 상당히 편리한 기능입니다.
이건 아직 잘 모르겟다..
나중에 업로드 할 예정이니 지켜봐주세요?
6. 결측치 찾기
데이터를 분석할때 결측치, 즉 NaN값이 있으면 정확한 분석이 어렵고, 오류가 발생하기도 한다.
그렇기 위해선 결측치를 찾아 제거하거나 다른 값으로 채워넣거나 0으로 만드는 방법 등이 있다.
결측치를 찾는 방법은 정말 여러개가 있다.
간단하게 .info() 메소드를 이용해서 볼 수 있고, isnull() (=isna()), notnull() (=notna()) 메소드를 이용할 수도 있다.
.isnull()을 사용하면 결측치는 true로 표시 되는데, 데이터 하나하나 True, False로 봐야하기때문에 단순히 null값을 알기위해서는 불편하다.
그래서 결측치의 갯수를 알수 있는 최고의 방법은
# 열의 결측치 개수 확인 -> null 몇개인지 확인 가능.
df.isna().sum()
df.isna().sum()/len(air) *100 # 결측치 비율
이 방법이다. isna().sum()을 사용하면 결측치가 몇개인지만 딱! 나온다!
7. 결측치 제거
결측치는 dropna()메소드로 열이나 행을 제거할 수 있다. 제거는 신중하게 해야해서 원본값을 복사해서 삭제하는게 좋다
복사는 dfTest = df.copy()
axis = 0 : 행 제거 (기본값)
axis = 1 : 열 제거
<어떤 열이든 결측치가 있는 행을 제거>
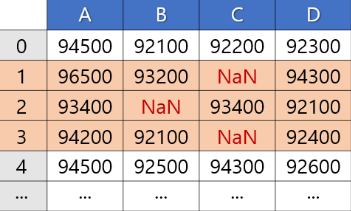
# 결측치가 하나라도 있는 행 제거
df.dropna(axis=0, inplace= True )
<결측치가 있는 열 중, 특정 행만 제거>
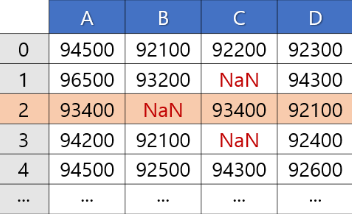
df.dropna(subset=['제거할 열이름'], axis=0, inplace = True)
<결측치가 있는 모든 열 제거>
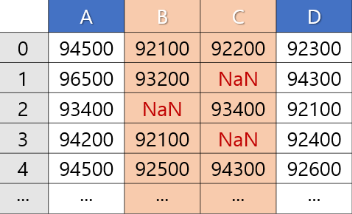
df.dropna(axis=1, inplace=True)
8. 결측치 채우기
fillna() 메소드로 채울 수 있다
<평균값으로 채우기>-- 그 열의 평균값을 구한 후 그 값으로 채우는 방법
# 데이터프레임 복사
df_test = df.copy()
# 열 이름이 'Ozone'인 열 평균 구하기
mean_Ozone = df_test['Ozone'].mean()
# 결측치를 평균값으로 채우기
df_test['Ozone'].fillna(mean_Ozone, inplace=True)
<특정 값으로 채우기>
# Solar.R 열의 누락된 값을 0으로 채우기
df_test['Solar.R'].fillna(0, inplace=True)
<직전 행의 값 또는 바로 다음행의 값으로 채우기>
- 결측치를 바로 앞이나 뒤의 값으로 채우는 방법.
- 날짜 or 시간의 흐름에 따른 시계열 데이터 처리시 유용하다.
- 바로 앞의 값으로 채우려면 ffill(), 뒤의 값으로 채우려면 bfill()
# Ozone 열의 누락된 값을 바로 앞의 값으로 채우기
df_test['Ozone'] = df_test['Ozone'].ffill()
# Solar.R 열의 누락된 값을 바로 뒤의 값으로 채우기
df_test['Solar.R'] = df_test['Solar.R'].bfill()
<선형보간법으로 채우기>
interpolate() 메소드를 사용한다.
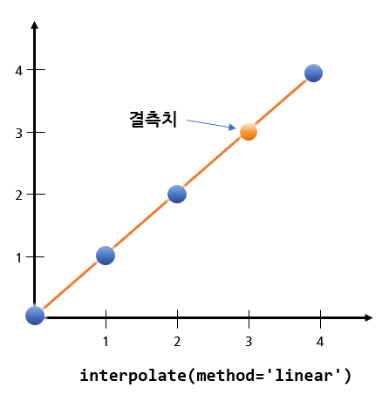
# 데이터프레임 복사
df_test = df.copy()
# 선형보간법으로 채우기
df_test.interpolate(method='linear', inplace = True)
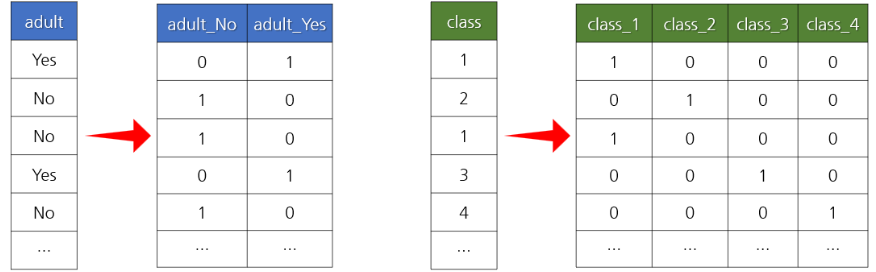
9. 가변수(Dummy Variable) 만들기
가변수 만들기는 문자열 데이터를 숫자로 바꾸는 역할, 숫자형을 숫자의 의미가 없게 하는 역할이 있다.
- 가변수는 일정하게 정해진 범위의 값을 갖는 데이터(범주형 데이터)를 독립된 열로 변환한 것입니다.
- 특히 범주형 문자열 데이터는 머신러닝 알고리즘에 사용하려면 숫자로 변환해야 합니다.
- 가변수를 만드는 과정을 One-Hot-Encoding 이라고 부르기도 합니다.
- get_dummies() 함수를 사용해서 가변수를 쉽게 만들 수 있습니다
'데이터 다듬기 > 데이터 다듬기' 카테고리의 다른 글
| 데이터프레임 메소드 정리2 (0) | 2024.09.24 |
|---|---|
| 데이터프레임 간단한 메소드 정리 (1) | 2024.09.18 |